bir eğitimcinin perspektifinden tidyverse
varsayımlar

varsayım 1:
otantik araçları öğretmeliyiz

varsayım 2:
otantik araç olarak R öğretelim
tidyverse
- çağrıldığında sekiz çekirdek paketi yükleyen ve ayrıca kurulum sırasında çok sayıda başka paketi bir araya getiren meta R paketi
- tidyverse paketleri bir tasarım felsefesini, ortak dil bilgisini, ve veri yapılarını paylaşır

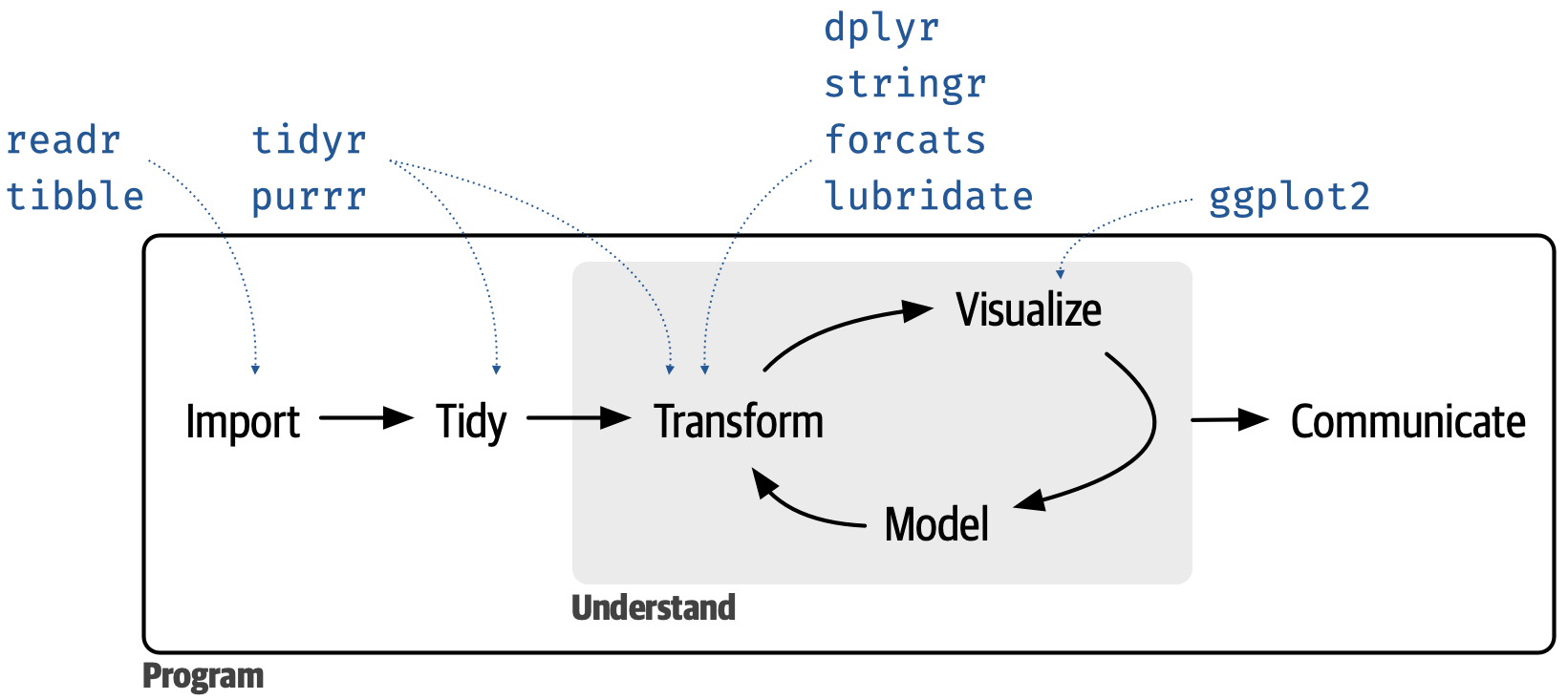
hedef: veri görselleştirme
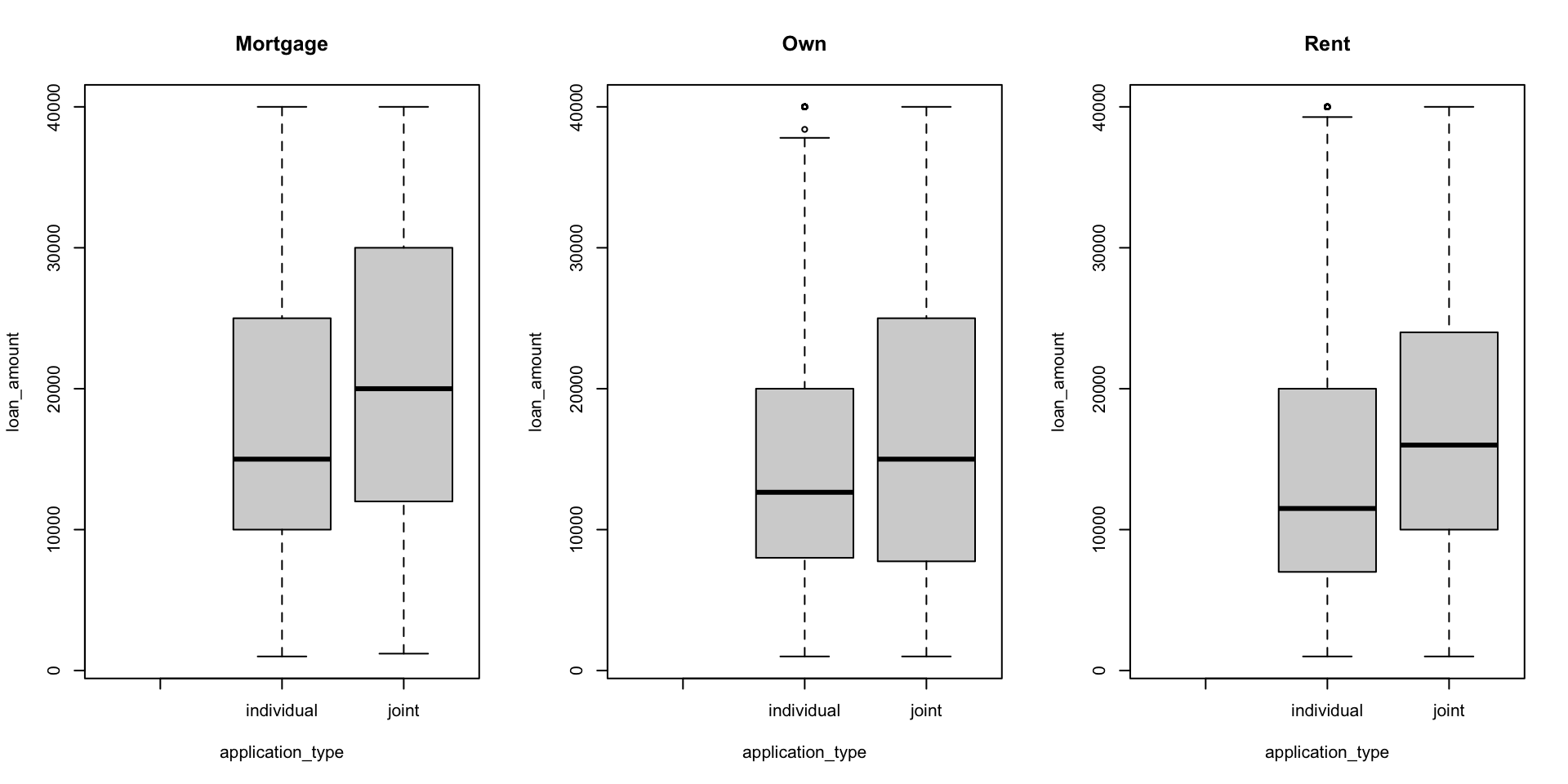
Borçlanma tutarı ile başvuru türü arasındaki ilişkiyi ev sahipliğine göre gösteren yan yana kutu grafikleri oluşturun.
adım adım I

adım adım II
adım adım III
adım adım IV
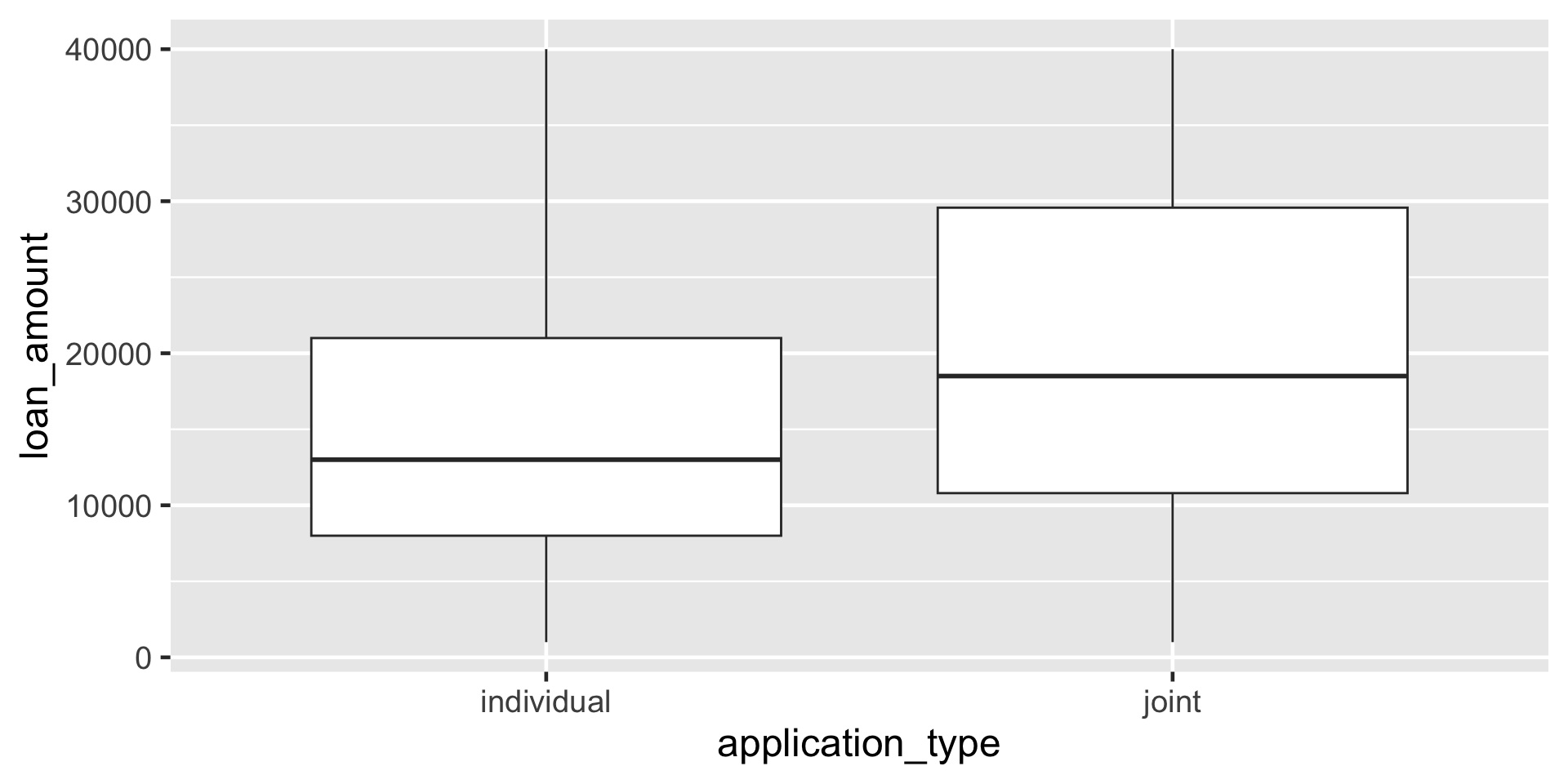
adım adım IV
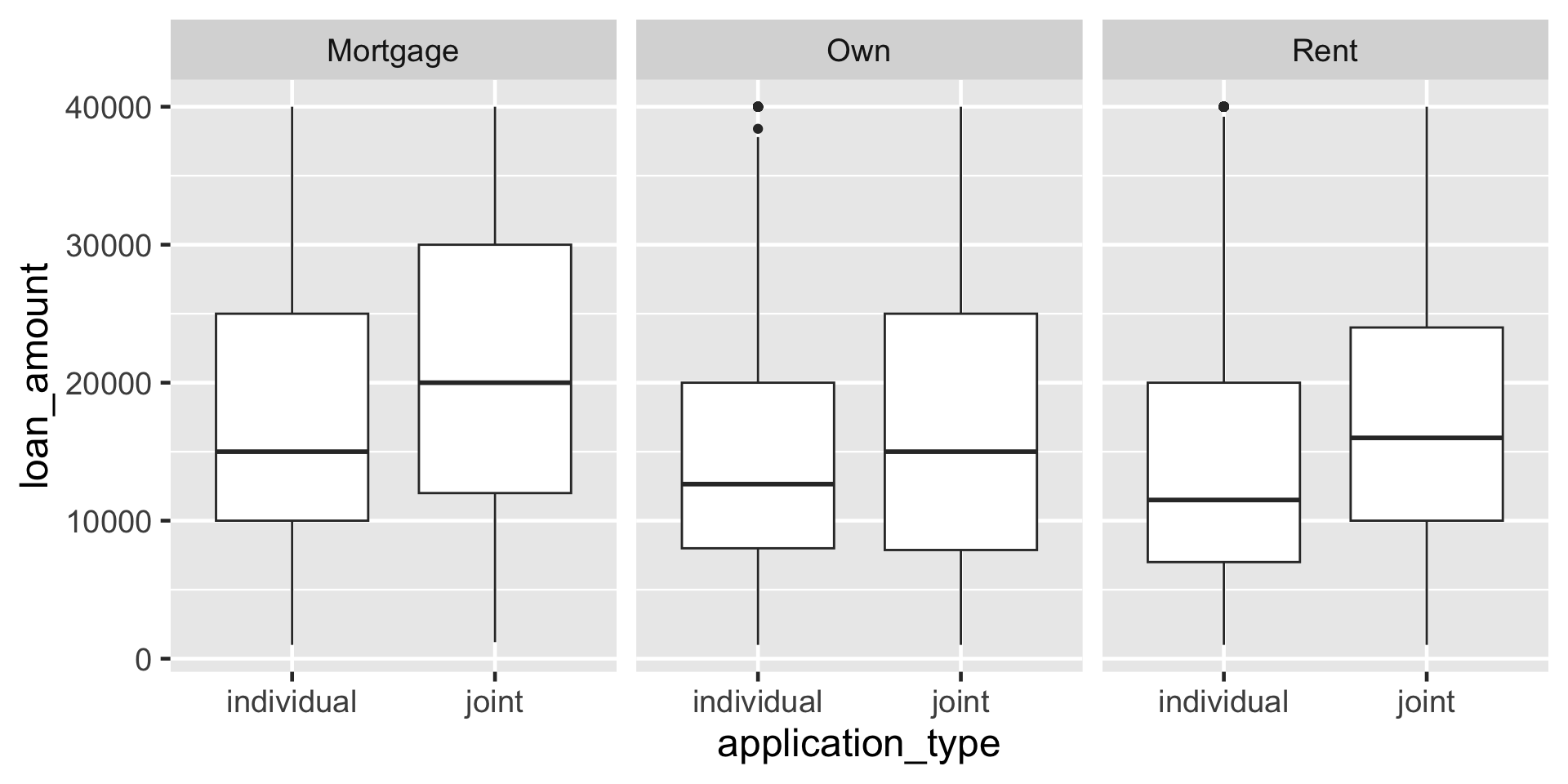
boxplot() ile görselleştirme
hedef: farklı bir ilişkiyi görselleştirmek
Faiz oranı ile yıllık gelir arasındaki ilişkiyi başvuranın iflasına bağlı olarak gözünüzde canlandırın.
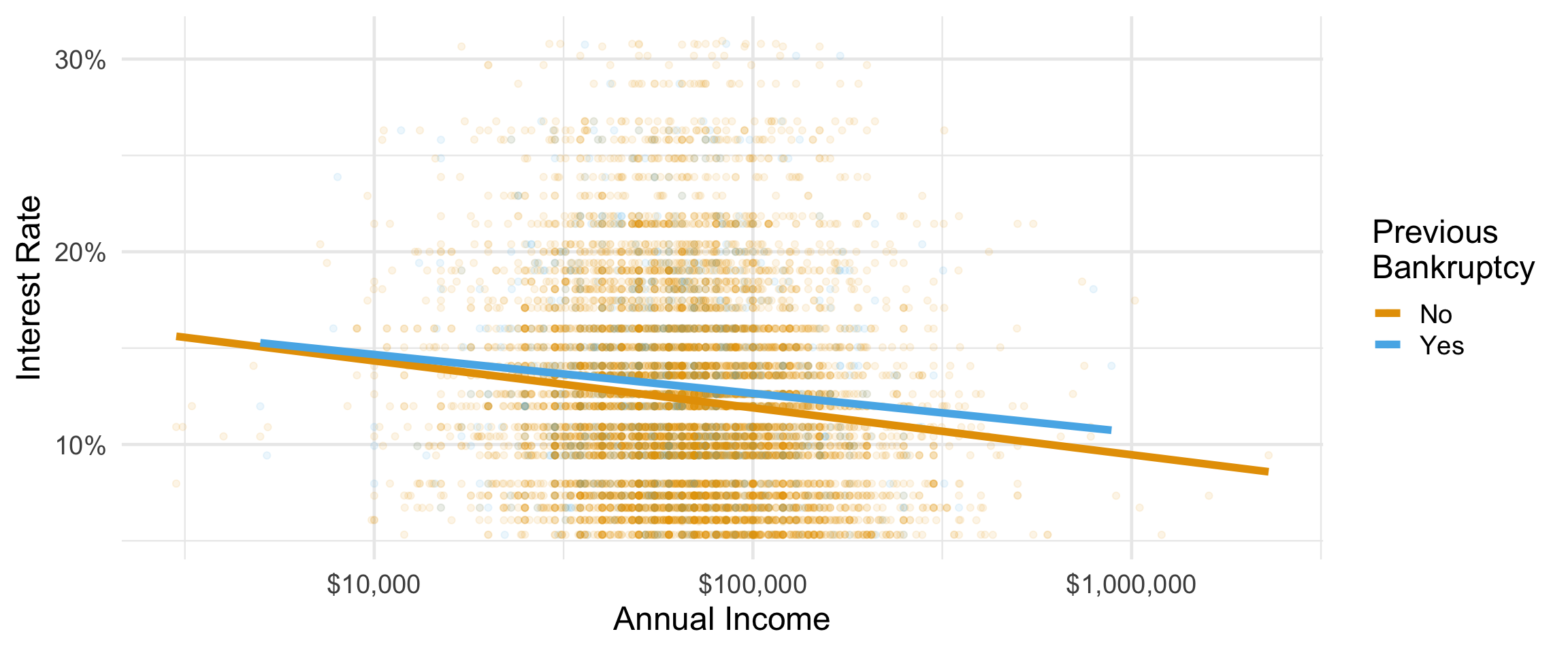
ggplot() ile görselleştirme
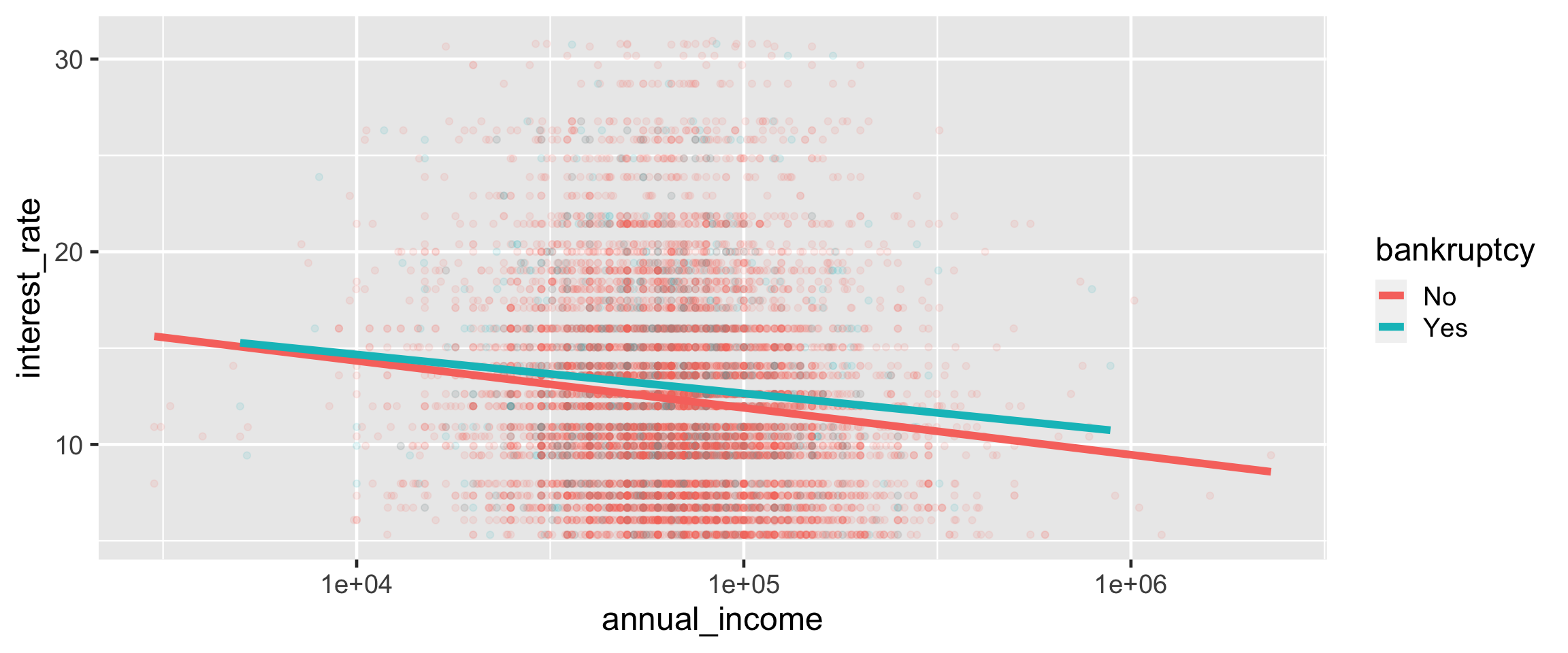
ggplot() ile özelleştirme
ggplot(loans,
aes(y = interest_rate, x = annual_income,
color = bankruptcy)) +
geom_point(alpha = 0.1) +
geom_smooth(method = "lm", linewidth = 2, se = FALSE) +
scale_x_log10(labels = scales::label_dollar()) +
scale_y_continuous(labels = scales::label_percent(scale = 1)) +
scale_color_OkabeIto() +
labs(x = "Annual Income", y = "Interest Rate",
color = "Previous\nBankruptcy") +
theme_minimal(base_size = 18)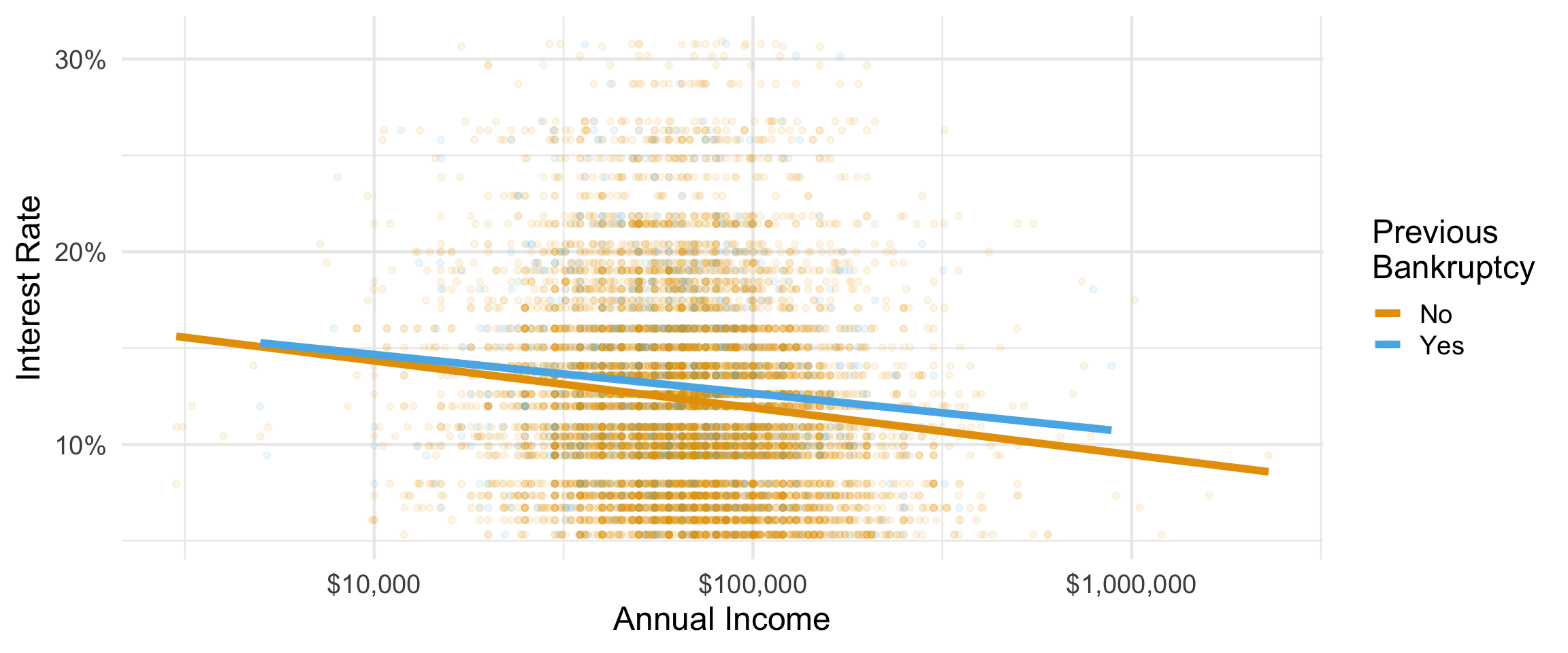
plot() ile görselleştirme
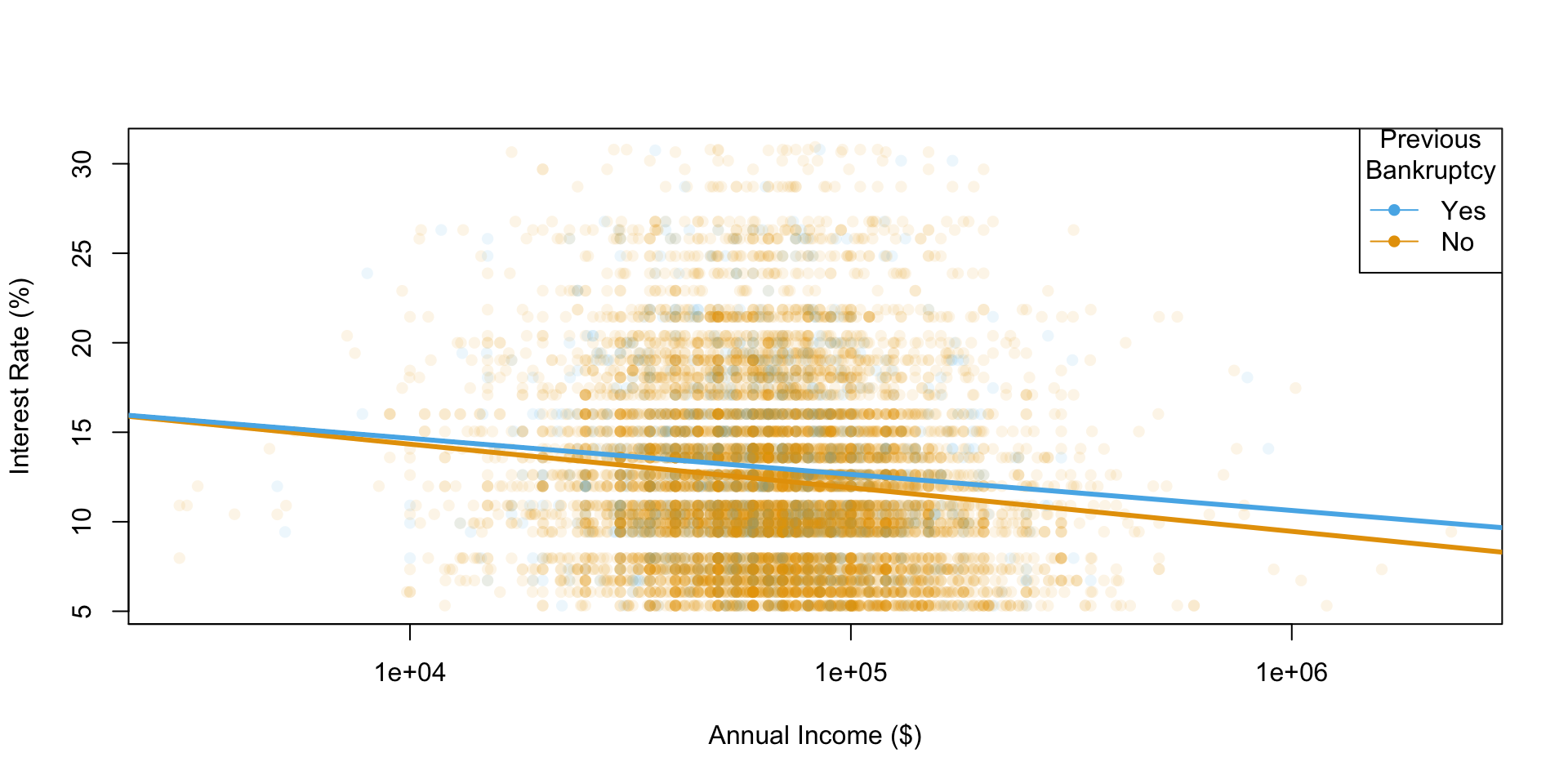
data science in a box

tidyverse’i takip etmek
blog gönderileri, güncellemeleri, bunların arkasındaki mantık ve işe yarayan örneklerle birlikte vurgular
-
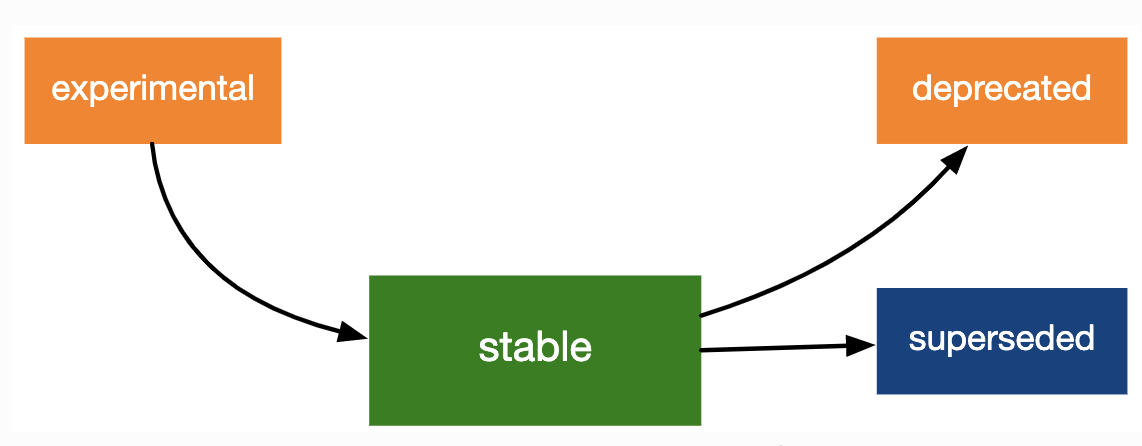
lifecycle stages (yaşam döngüsü aşamaları) ve rozetler
![Lifecycle stages: experimental to stable to either deprecated or superseded]()
koda
Her birimiz R’i tidyverse oncesinde öğrendik ve senelerce tidyverse’siz R ogrettik. Daha sonra araştırmamızda ve öğretimimizde tidyverse’i kullanmaya karar verdik. Bu makale, tidyverse seçimimizi destekleyen nedenlerin yanı sıra, tidyverse ile istatistik öğretiminin faydalarının ve zorluklarının bir sentezidir.
