an educator’s perspective of the tidyverse
introduction
collaborators
- Johanna Hardin, Pomona College
- Benjamin S. Baumer, Smith College
- Amelia McNamara, University of St Thomas
- Nicholas J. Horton, Amherst College
- Colin W. Rundel, Duke University
setting the scene

Assumption 1:
Teach authentic tools

Assumption 2:
Teach R as the authentic tool
takeaway
The tidyverse provides an effective and efficient pathway for undergraduate students at all levels and majors to gain computational skills and thinking needed throughout the data science cycle.
principles of the tidyverse
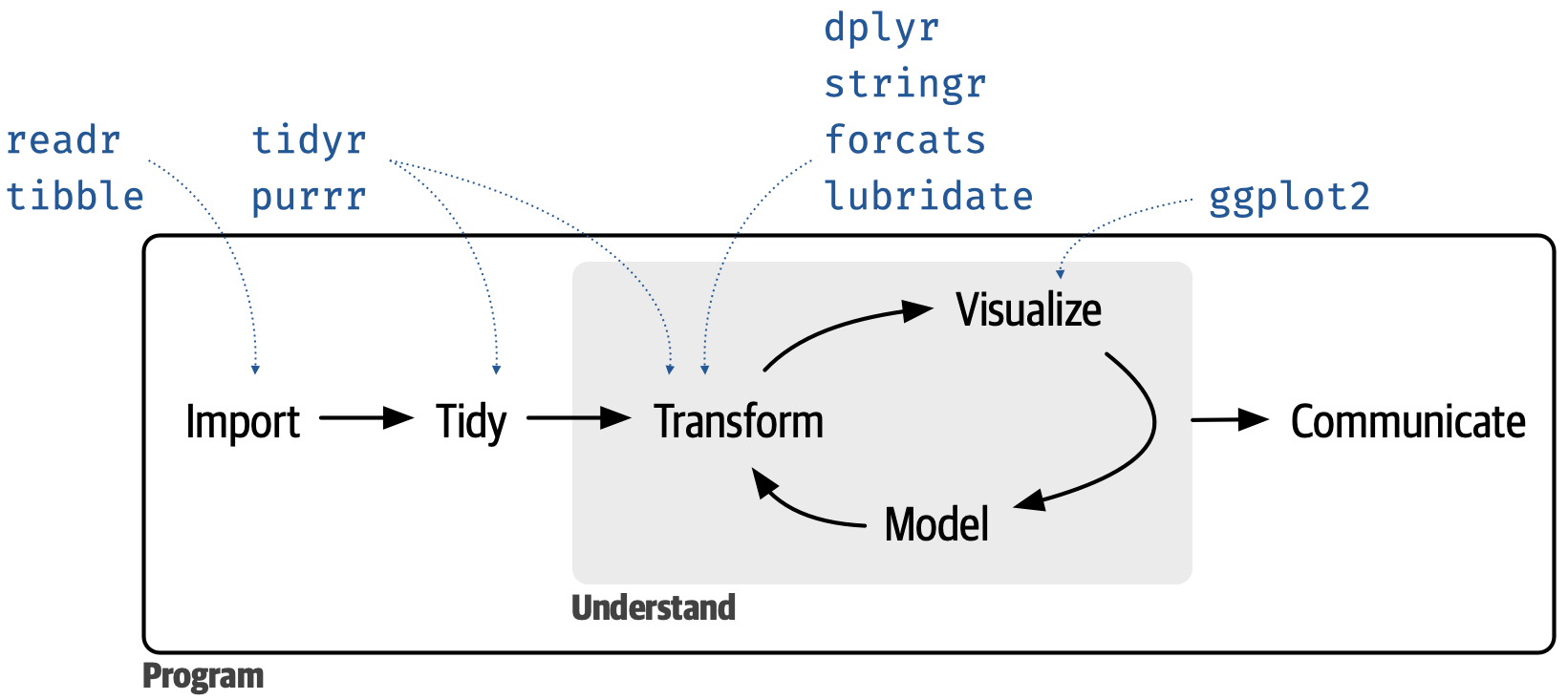
tidyverse
- meta R package that loads eight core packages when invoked and also bundles numerous other packages upon installation
- tidyverse packages share a design philosophy, common grammar, and data structures

setup
Data: Thousands of loans made through the Lending Club, a peer-to-peer lending platform available in the openintro package, with a few modifications.
library(tidyverse)
library(openintro)
loans <- loans_full_schema %>%
mutate(
homeownership = str_to_title(homeownership),
bankruptcy = if_else(public_record_bankrupt >= 1, "Yes", "No")
) %>%
filter(annual_income >= 10) %>%
select(
loan_amount, homeownership, bankruptcy,
application_type, annual_income, interest_rate
)start with a data frame
# A tibble: 9,976 × 6
loan_amount homeownership bankruptcy application_type annual_income interest…¹
<int> <chr> <chr> <fct> <dbl> <dbl>
1 28000 Mortgage No individual 90000 14.1
2 5000 Rent Yes individual 40000 12.6
3 2000 Rent No individual 40000 17.1
4 21600 Rent No individual 30000 6.72
5 23000 Rent No joint 35000 14.1
6 5000 Own No individual 34000 6.72
# … with 9,970 more rows, and abbreviated variable name ¹interest_ratetidy data
- Each variable forms a column
- Each observation forms a row
- Each type of observational unit forms a table
task: calculate a summary statistic
Calculate the mean loan amount.
# A tibble: 9,976 × 6
loan_amount homeownership bankruptcy application_type annual_income interest…¹
<int> <chr> <chr> <fct> <dbl> <dbl>
1 28000 Mortgage No individual 90000 14.1
2 5000 Rent Yes individual 40000 12.6
3 2000 Rent No individual 40000 17.1
4 21600 Rent No individual 30000 6.72
5 23000 Rent No joint 35000 14.1
6 5000 Own No individual 34000 6.72
# … with 9,970 more rows, and abbreviated variable name ¹interest_rateError in mean(loan_amount): object 'loan_amount' not foundaccessing a variable
Approach 1: With attach():
Not recommended. What if you had another data frame you’re working with concurrently called car_loans that also had a variable called loan_amount in it?
accessing a variable
Approach 2: Using $:
accessing a variable
Approach 4: The tidyverse approach:
# A tibble: 1 × 1
mean_loan_amount
<dbl>
1 16358.- More verbose
- But also more expressive and extensible
the tidyverse approach
tidyverse functions take a
dataargument that allows them to localize computations inside the specified data framedoes not muddy the concept of what is in the current environment: variables always accessed from within in a data frame without the use of an additional function (like
with()) or quotation marks, never as a vector
teaching with the tidyverse
task: grouped summary
Based on the applicants’ home ownership status, compute the average loan amount and the number of applicants. Display the results in descending order of average loan amount.
| Homeownership | Number of applicants | Average loan amount |
|---|---|---|
| Mortgage | $18,132 | 4,778 |
| Own | $15,665 | 1,350 |
| Rent | $14,396 | 3,848 |
break it down I
Based on the applicants’ home ownership status, compute the average loan amount and the number of applicants. Display the results in descending order of average loan amount.
# A tibble: 9,976 × 6
loan_amount homeownership bankruptcy application_type annual_income interest…¹
<int> <chr> <chr> <fct> <dbl> <dbl>
1 28000 Mortgage No individual 90000 14.1
2 5000 Rent Yes individual 40000 12.6
3 2000 Rent No individual 40000 17.1
4 21600 Rent No individual 30000 6.72
5 23000 Rent No joint 35000 14.1
6 5000 Own No individual 34000 6.72
# … with 9,970 more rows, and abbreviated variable name ¹interest_ratebreak it down II
Based on the applicants’ home ownership status, compute the average loan amount and the number of applicants. Display the results in descending order of average loan amount.
[input] data frame
# A tibble: 9,976 × 6
# Groups: homeownership [3]
loan_amount homeownership bankruptcy application_type annual_income interest…¹
<int> <chr> <chr> <fct> <dbl> <dbl>
1 28000 Mortgage No individual 90000 14.1
2 5000 Rent Yes individual 40000 12.6
3 2000 Rent No individual 40000 17.1
4 21600 Rent No individual 30000 6.72
5 23000 Rent No joint 35000 14.1
6 5000 Own No individual 34000 6.72
# … with 9,970 more rows, and abbreviated variable name ¹interest_ratedata frame [output]
break it down III
Based on the applicants’ home ownership status, compute the average loan amount and the number of applicants. Display the results in descending order of average loan amount.
break it down IV
Based on the applicants’ home ownership status, compute the average loan amount and the number of applicants. Display the results in descending order of average loan amount.
break it down V
Based on the applicants’ home ownership status, compute the average loan amount and the number of applicants. Display the results in descending order of average loan amount.
putting it back together
[input] data frame
loans %>%
group_by(homeownership) %>%
summarize(
avg_loan_amount = mean(loan_amount),
n_applicants = n()
) %>%
arrange(desc(avg_loan_amount))# A tibble: 3 × 3
homeownership avg_loan_amount n_applicants
<chr> <dbl> <int>
1 Mortgage 18132. 4778
2 Own 15665. 1350
3 Rent 14396. 3848[output] data frame
grouped summary with aggregate()
grouped summary with aggregate()
grouped summary with aggregate()
- Good: Inputs and outputs are data frames
-
Not so good: Need to introduce
formula syntax
passing functions as arguments
merging datasets
square bracket notation for accessing rows
grouped summary with tapply()
Mortgage Own Rent
18132.45 15665.44 14396.44 Not so good:
- passing functions as arguments
- distinguishing between the various
apply()functions - ending up with a new data structure (
array) - reading nested functions
and…
many more comparative examples in the paper
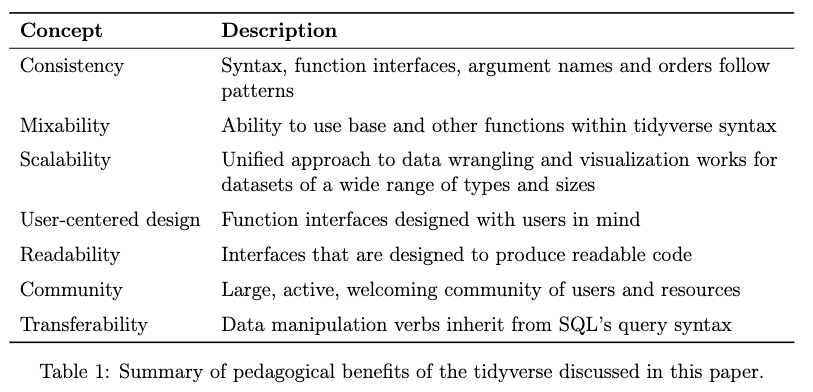
pedagogical strengths of the tidyverse
coda
We are all converts to the tidyverse and have made a conscious choice to use it in our research and our teaching. We each learned R without the tidyverse and have all spent quite a few years teaching without it at a variety of levels from undergraduate introductory statistics courses to graduate statistical computing courses. This paper is a synthesis of the reasons supporting our tidyverse choice, along with benefits and challenges associated with teaching statistics with the tidyverse.
